EcoService Models Library (ESML)
 Home
Home Search EMs
Search EMs My
EMs
My
EMs  Learn about
ESML
Learn about
ESMLUsing the ESML Variable Classification Hierarchy to categorize EM variables
Explore the Variable Classification Hierarchy Browser (only works in Chrome or Firefox)View the Variable Classification Hierarchy (XLSX)
Purpose
Model variables convey much information regarding the functioning of an ecological model, the potential benefits of using the model, and its logistical difficulties. The predictor, intermediate and response variables indicate what is being estimated and what kinds of causal inferences or associations can or cannot be made. An ability to search models based on variable types is valuable. Variable names themselves do not enable this, because in a large database like ESML there are too many names, and their meanings may not be understandable from the name alone. A classification system that bins variables into informative categories can enable searching and investigation of models based on their variable characteristics.
Objective
Categorize model variables so that:
- ESML users can locate all models that include a variable type that is of interest (e.g., mammals; nitrogen processing), regardless of how the variables are named in the model.
- ESML users can search for models that combine multiple variables of interest (e.g., coastal habitat and fish harvest; wetland characteristics and recreation visits; wind turbines and coastal recreation; tree cover, temperature, and stream flow).
- ESML users can identify potential linkages between models -- for example, model 1 has nitrogen attenuation as a response variable; model 2 has nitrogen concentration as a predictor variable and recreation as a response variable.
Structure
The Variable Classification Hierarchy (VCH) has four levels. The categorization of any given variable uses at least two and as many as four of these levels.
The seven categories comprising the top level (shown in the figure below) are intended to be comprehensive of all possible model variables. Levels 2 - 4 (which may be viewed using the VCH Browser or VCH Spreadsheet; see links above) are not necessarily comprehensive -- that is, they are designed based on the existing variables in ESML; more subcategories at each level could be defined in the future to categorize new types of variables as they are added.
Approach
- The classification system has been built based on the set of variables at hand (i.e., ~1900 variables derived from ~150 models or model applications), not based on a theoretical universe.
- Individual variables are classified based on their definitions, independent of their relationships to other variables.
- Examine contributing variables to ensure accurate classification of ambiguously named variables.
The existing variable set in ESML is extensive and will be taken as sufficiently representative of ecological model variables. It is assumed that a classification system that accommodates these variables will be robust. While modifications may be needed to accommodate different variables in the future, the intended strategy is to build a sufficient system using the present variables rather than create a more extensive system to contain potential variable types not yet encountered.
This classification system seeks to enable users to find all models that include variables of a particular type, assuming the user who is interested in that variable would benefit from seeing it used in different computational settings. Therefore, the system focuses on classifying each variable according to what quantity or quality it denotes, independent of how it relates to other variables in the model, because those relationships will naturally differ from model to model.
For example, there is no variable category for “Final Ecosystem Goods and Services,” because identification of FEGS requires the association of an ecological attribute with a human beneficiary, whereas a given variable would most often describe one or the other. Even when a single variable does combine aspects of both (such as a variable that quantifies human populations located in proximity to specific environmental amenities), it is often difficult to determine whether the association (proximity in this case) entails a direct and recognized benefit (as FEGS designation would require). Similar problems occur when trying to determine which ecosystem processes should be considered to be intermediate ecosystem services. Therefore, all ecological processes and attributes, including those that potentially provide intermediate or final ecosystem goods and services, are grouped together in a single, top-level class including ecological attributes, processes and supply of ecosystem services. When variables have both ecological and social attributes, such as the proximity variable just described, the top-level classification depends on whether the variable primarily describes the ecological supply of the attribute (Category 5) or human demand/use/enjoyment associated with the attribute (Category 6 if units are nonmonetary, Category 7 if monetary).
Similarly, although ecosystem-service modeling may seek to quantify economic benefit, the system does not include a category for economic benefit per se. Even an unambiguously named variable such as “income net of costs” would constitute an economic benefit only if it was computed in reference to an appropriate counterfactual (e.g., computed with and without a given intervention). This determination could be made at the level of the model, but not at the level of the variable. Therefore, while variables generally related to human demand/use/enjoyment of resources are classified as Category 6 if units are nonmonetary and Category 7 if monetary, economic benefit per se is not a basis for classification.
While classification is based on each individual variable and not its relationship to other variables, accurate classification of a given variable may require examining other variables – not to determine relationship, but to ensure correct definition. Variable names are sometimes ambiguous, and it may be necessary to look at the variables contributing to it to gain a clear definition. For example, a variable that modelers have named “Potential value of open space” might appear related to economic value, but examination of its contributors shows that the variable describes only whether a parcel’s land cover falls within an open-space definition. Open-space is a broad category of land cover type, and does not address actual human demand or value. The variable is therefore categorized as Category 2, Land Surface (or Water Body Bed) Cover, Use or Substrate.
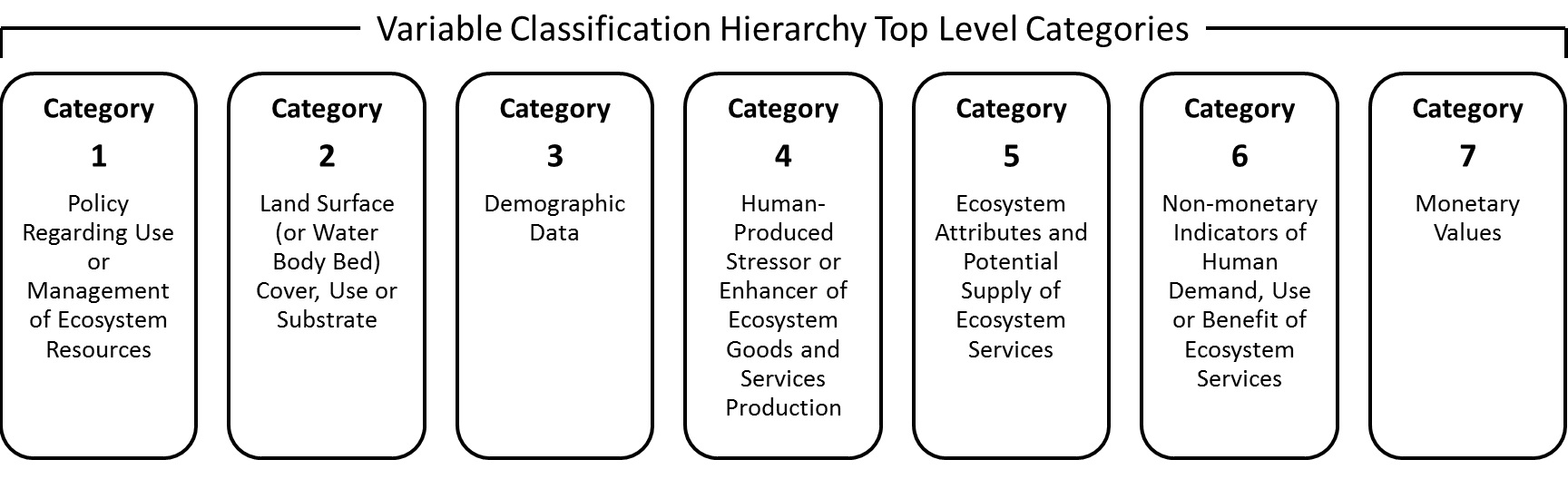
For further details on variable category classification, see Further Explanation of top-level variable categories in the Variable Classification Hierarchy.